
Intro
Enterprise teams are now evaluating two very different approaches to retrieval-augmented generation (RAG): model-centric optimization research and production-grade RAG systems that must run inside real operating environments. Databricks' KARL paper (published March 5, 2026) is one of the strongest examples of the first category. Akila's RAG pipeline is built for the second.
This matters because most CIOs and business leaders are not deciding between two papers; they are deciding between two execution paths. One path optimizes the policy inside an agent. The other path must handle ingestion quality, document governance, retrieval quality, grounding, observability, cost controls, and business workflow integration.
Summary
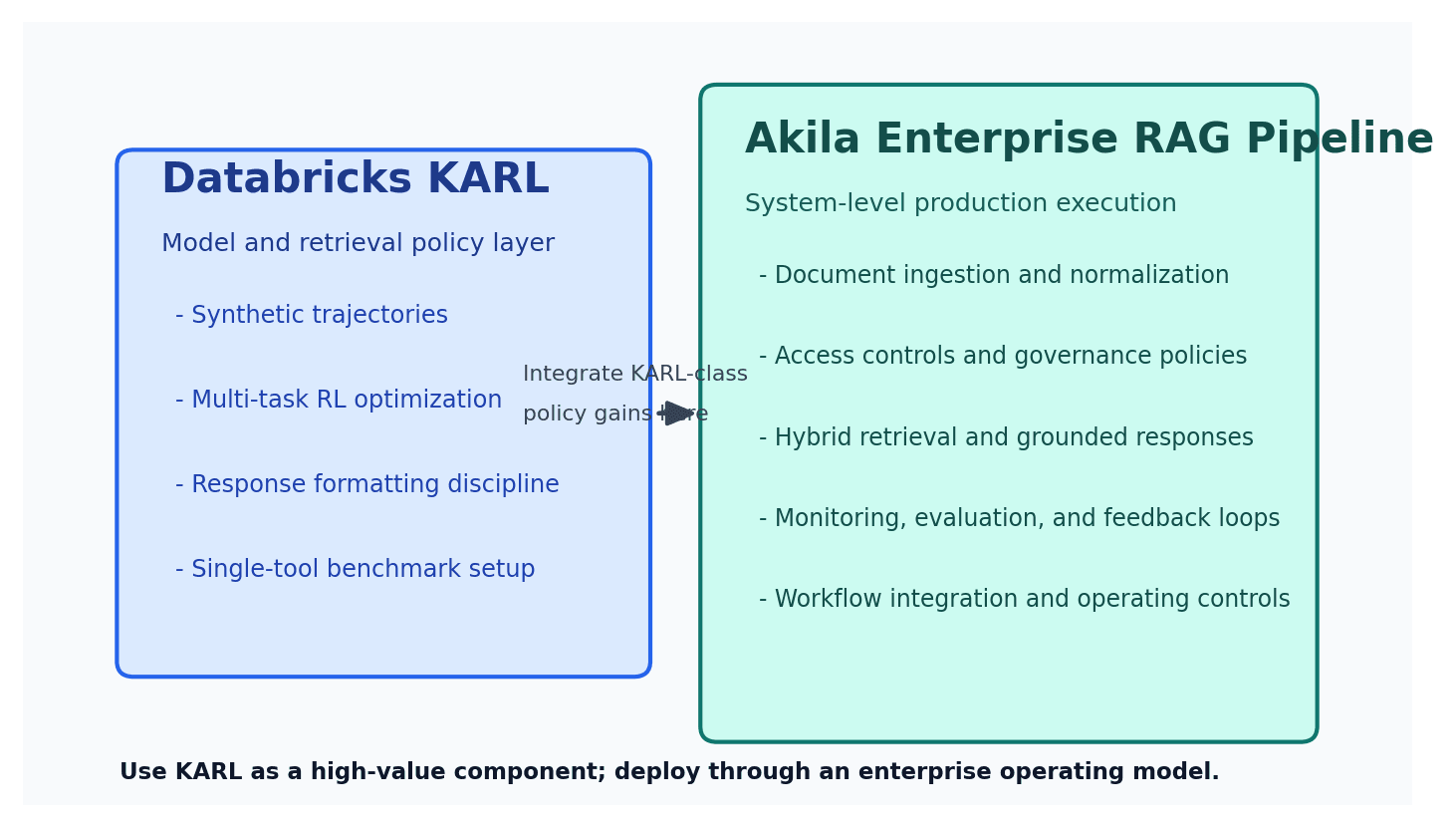
KARL is a meaningful technical contribution. In the paper, Databricks reports that KARL reaches frontier-quality retrieval performance at materially lower cost and latency on its benchmark suite, and it explicitly frames this as a post-training approach for search agents. The paper is especially strong on synthetic trajectory generation, multi-task reinforcement learning, and response formatting discipline.
At the same time, KARL is not the same thing as an enterprise RAG pipeline. The paper currently evaluates an agent with a single tool (Vector Search), a constrained action space, and a benchmark setup that includes proprietary PMBench tasks. That is a valid and useful research design, but it is not yet a full operating blueprint for enterprise document intelligence programs.
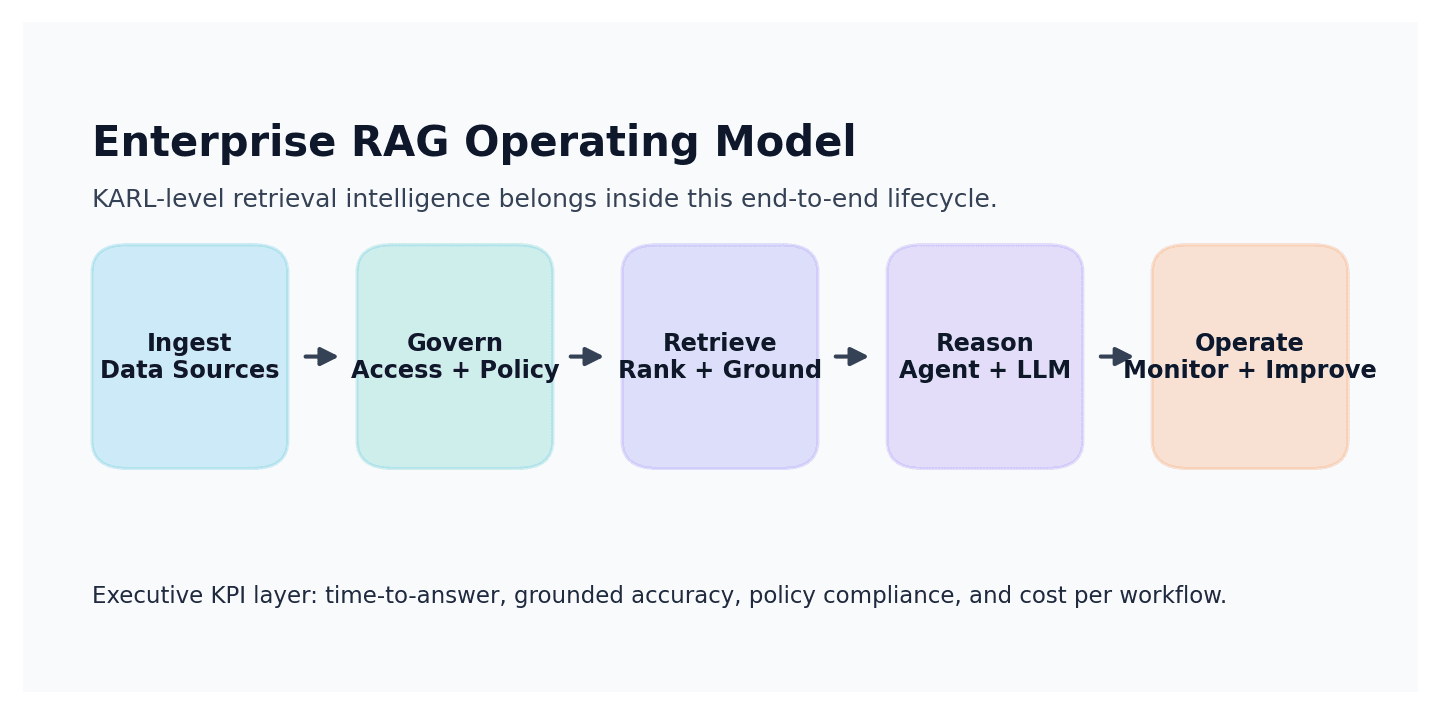
Akila's RAG pipeline is designed as an end-to-end enterprise system. The goal is not only answer quality; it is reliable business execution under data variability, compliance constraints, and multi-team ownership. In practice, that means the pipeline is engineered around ingestion reliability, retrieval precision and recall, source-grounded responses, governance controls, and operational visibility for non-ML stakeholders.
The economics lens is also different. KARL optimizes model behavior and token-level efficiency. Akila optimizes total operating economics: document onboarding effort, indexing and refresh orchestration, answer quality assurance, exception handling, and recurring support burden across business units. For executive teams, this system-level view usually determines ROI more than model-only gains.
The right synthesis is pragmatic: learn from KARL's training insights, then deploy through a pipeline architecture that can survive enterprise reality. In other words, KARL is a strong component-level innovation; Akila is the operating system around that class of innovation.
Akila RAG Pipeline vs KARL: Side-by-Side
| Dimension | Akila RAG Pipeline | Databricks KARL | |---|---|---| | Primary objective | Business-ready enterprise RAG outcomes | Post-training optimization of retrieval agents | | System scope | End-to-end pipeline (data-to-decision) | Agent policy + retrieval behavior | | Tooling model | Multi-stage enterprise workflows and controls | Paper setup currently uses a single Vector Search tool | | Evaluation focus | Grounded accuracy, business usability, governance, operational reliability | Benchmark quality, latency, and cost frontier | | Deployment posture | Built for ongoing production operations and cross-functional ownership | Research-to-product bridge, with strong but scoped benchmark evidence | | Economics | Total cost of ownership across ingestion, retrieval, monitoring, and operations | Token/latency efficiency gains on benchmarked workloads | | Governance and risk | Designed for enterprise policy, data stewardship, and reproducibility | Not the central focus of the KARL paper | | Executive decision value | Highest when teams need dependable execution in live business contexts | Highest when teams need a stronger retrieval policy baseline |
What KARL Gets Right
KARL correctly identifies that enterprise retrieval agents need policy learning, not just bigger prompts. The paper's multi-task RL approach, synthetic trajectory generation, and explicit formatting constraints are directionally right for serious enterprise use. Databricks also reports compelling benchmark economics: under $0.10 per 1K notes at 81.8% quality in its setup, plus better latency/cost tradeoffs than selected large-model baselines at comparable quality.
From Akila's perspective, these are useful ideas to absorb, especially around retrieval policy optimization and reward design. They should be treated as building blocks, not the full stack.
Where Enterprise Teams Need More Than KARL
Enterprise RAG failure modes usually appear outside the model core:
- ingestion and normalization quality across heterogeneous documents
- access controls and policy-safe retrieval paths
- source lineage and evidence traceability for high-stakes decisions
- continuous evaluation with business-owned feedback loops
- predictable operations across changing data, users, and workflows
This is where pipeline architecture determines success. A retrieval policy can be excellent and still fail if the surrounding data and control plane is weak. Akila's design priority is to make these non-model layers first-class so AI outputs remain reliable under production stress.
Practical Decision Framework
If you are leading platform strategy, four questions typically separate research fit from production fit:
- Do we need a better agent policy, or a full enterprise RAG operating model?
- Are our constraints mostly model-performance constraints, or governance and operational constraints?
- Can we absorb a research-grade component into our stack, or do we need a production-ready pipeline now?
- Are we optimizing benchmark metrics, or business outcomes tied to adoption, trust, and repeatability?
If your organization is in experimentation mode, KARL-like advances are high value. If your organization is in delivery mode with multiple business stakeholders, pipeline-first architecture usually wins.
Conclusion
KARL is an important retrieval-agent advance and a credible signal of where model-level enterprise search optimization is going. But model-level optimization is only one layer of enterprise RAG. Akila's RAG pipeline is built around the broader requirement: sustained, governed, and economically efficient business execution from enterprise documents and data.
For business leaders, the practical answer is not "KARL or pipeline." It is to use KARL-class methods where they help, inside an enterprise architecture that is explicitly engineered for production reliability, governance, and measurable business outcomes.
Sources
- KARL: Learning to Retrieve and Reason in Language Models (Databricks, March 5, 2026)
- Instructed Retriever: Unlocking System-Level Reasoning in Search Agents (Databricks Blog)
- Agent Bricks Knowledge Assistant (Databricks Docs)
- Databricks Vector Search (Databricks Docs)
- Evaluate and monitor GenAI applications with MLflow 3 (Databricks Docs)
- Use Lakeflow Connect for SharePoint in RAG applications (Databricks Docs)